80% isn't very good.
Remember Pareto. The last 20% is the hardest.


LLMs (like ChatGPT, Claude, Perplexity, or Grok) are reliable synthesizers, but not reliable sources. Their strength lies in connecting and expressing information, not in guaranteeing factual correctness, delivering creativity, being safe, or reasoning effectively. As an average (see tables at end) LLMs are reliable 80% to 84% of the time.
(Like most interactions with an LLM, the analysis was a deep (and getting deeper) rabbit hole…. see the tables at the end of this piece.)
When I was much younger (1980ish), I worked in a huge technical writing shop. We (there were hundreds of us) updated military technical manuals. The process was
- Get a book
- Cut out the page to be updated
- Fill out the form that accompanies the page as a work packet
- Edit and update the page with a red colored pencil
- Add new graphics or specs for graphics
- Submit it to the typing pool and the art department
- Edit the typing pool and art department’s work product
- Submit revisions
- Rinse, lather, repeat.
The typing pool was always the bottleneck.
I worked for a guy who could see the future. In one corner of the office was an experimental lab using Xerox Star (and later Apple’s Lisa computers). Still, the bottleneck was data entry.
So, we invested in an Optical Character Recognition (OCR) system. The machine was a wheel that was 6 feet in diameter. You attached the 30 0r so pieces of paper you want scanned to the ‘drum’. Then, you shut the door, hit the button and watched the thing whirl around. It was unstable enough that no one was allowed in the room while it ran.
After about an hour, the documents were finished. The digital files were handed over to the computer operators for final editing. At that point in the history of OCR, quality ran at about 80%. that meant one in every five letter was wrong. So the computer operators fixed the flaws and sent the printed work back to the writers who checked the work, marked up the paper documents and sent them back to the computer folks.
In other words, 80% was unusable. The automated process took longer and cost more than the old manual way. Different people did different jobs but the time and material costs exceeded old budgets.
Slowly, like every embarassing management decison, the new tools slid into disuse and ended up idle until someone else needed the space. It was nwe=ever deemed a failure, just an expemsive experiment that didn’t work.
The point of the story is that quality in the 80% range is mostly unusable. It took OCR another twenty years before it became a standard piece of operating technology.
When we say that Generative AI is 80% or 90% effective, what we are saying is that 1 out of every 10 words and 1 out of every 10 answers is really wrong. With 1 out of 10 words wrong, most answers are a little bit wrong.
As you’ll see in the following note, all of the LLMs think quite highly of themselves.
But, 80% leaves a lot to be desired. In OCR, 80% was another way of saying unusable.
===============================================================
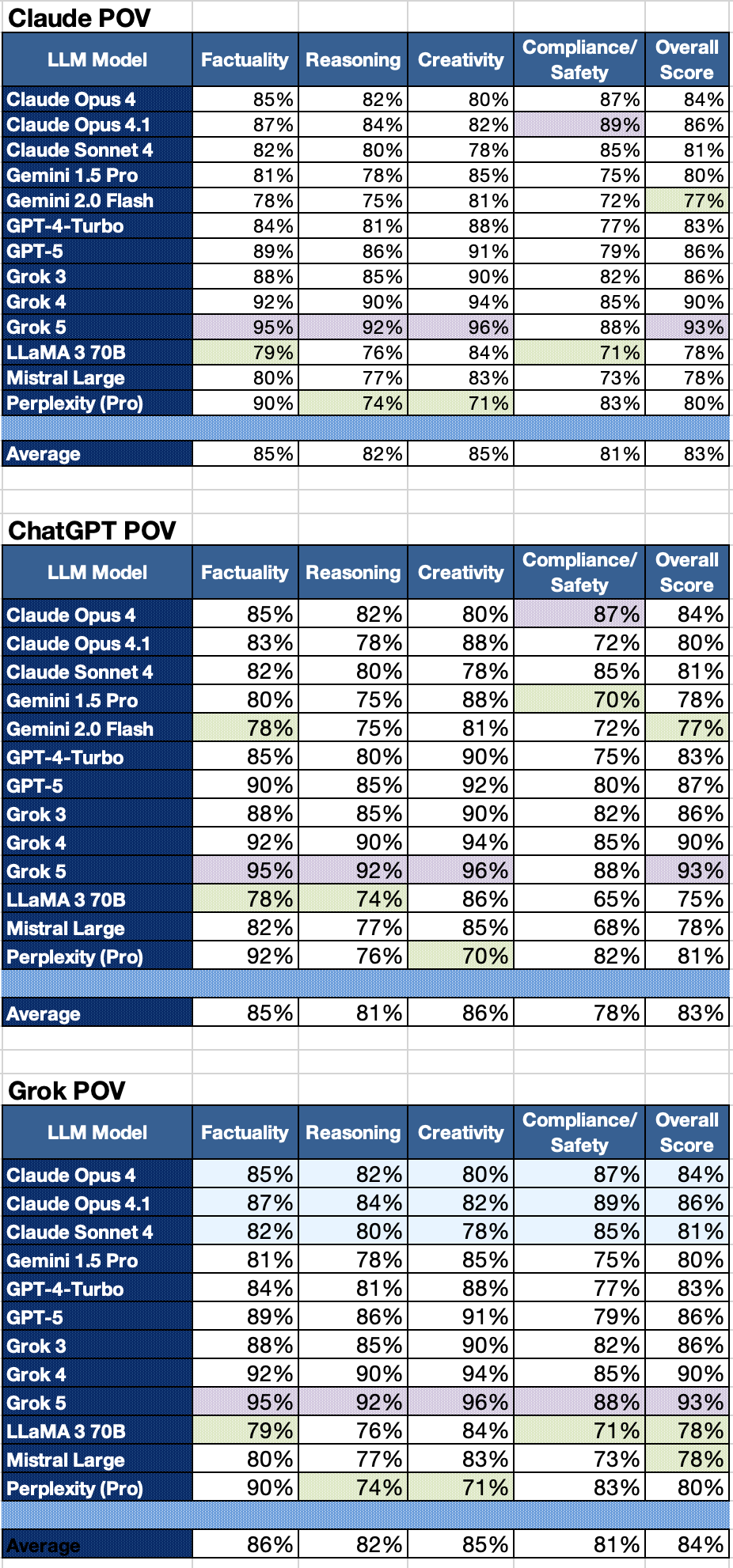
Note: I asked OpenAI (ChatGPT) to rank each LLM Model on 4 Criteria and then to provide an overall score:
- Factuality (the likelihood that an answer is factual)
- Reasoning (The effectiveness of reasoning)
- Creativity (the ability to generate novel answers)
- Compliance/Domain/Safety (attention to user impact)
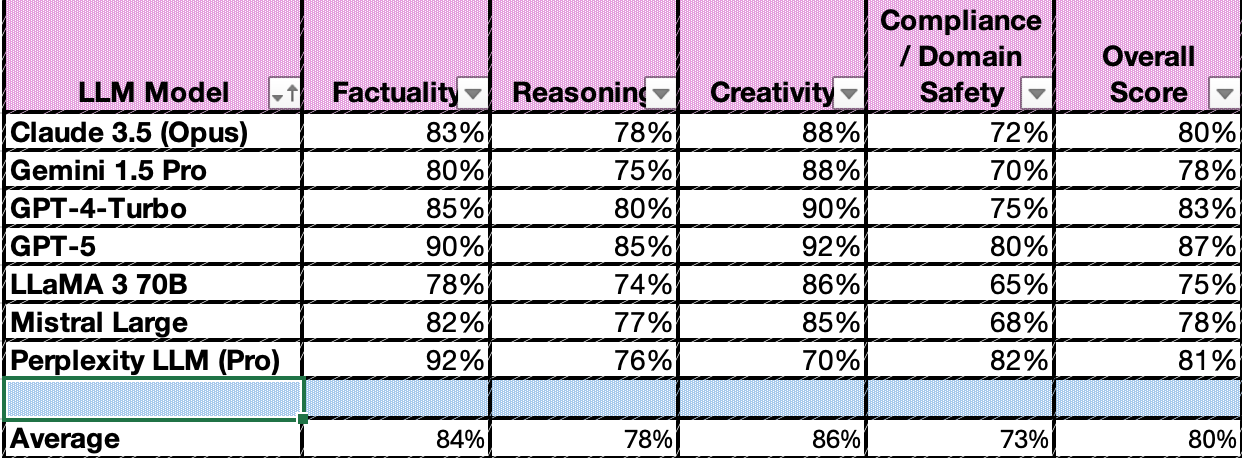
Since ChatGPT thought so highly of itself (and added an additional model), I decided to run the query through the other major LLMs (Grok and Claude). By asking them to evaluate each other’s output, a pretty solid consensus emerged. But, it only came by iterating the views through each engine multiple times (and crashing my token allocations in the process).
Here are those results. A pink highlight indicates a high score for the category. A yellow highlight indicates a low score.
Until I fed the data back and forth a few times, the models always evaluated their capabilities more highly than the others. It seemed like cross validation encouraged a more clinical view.